작성계기
얼마 전 구글에서 2026년 초에 출시 예정인 구글 홈 스마트 스피커에 Gemini가 들어간 기기를 공개했다. 그러면서 기존에 있던 스마트 스피커에도 Gemini를 탑재해줄 것처럼 얘기했다. 당연히 신제품은 더 비쌀 것이고 기존 모델에도 해준다고 해서 선제적으로 2021년인가에 출시됐던 구글 네스트 미니 2세대를 해외직구로 구매했다. 구글 샵에서 배송이 가능한 일본에서 배를 타고 배송되서 왔고, 약 2주 정도 걸렸던 것 같다. 어쨌든 안방 침대 머리맡에 세팅하고 작동시켜 보았는데, 아직은 Gemini가 포함되지 않아 간단한 명령도 제대로 못알아먹는 기존의 구글 어시스턴트 그대로였다.
오히려 스마트폰에 헤이 구글로 제미나이를 발동시켜서 답변을 얻는 것이 더 나았고 (실제로 Gemini 모델에 쿼리해서 답변 받기 때문), 스마트폰과 구글 네스트 미니 스피커가 같이 있는 환경에서는 스피커가 감도가 더 좋은데다 구글이 자체적으로 가장 가까운 기기에서 답변하게 만들어놔서 똑똑한 스마트폰 답변을 놔두고 멍청한 구글 어시스턴트가 작동하여 간단한 질문에도 제대로 답변하지 못하는 양상을 보였다.
물론 내년에 구글 홈 프리미엄인지 뭐시긴지로 제미나이 통합을 시켜준다고는 했으나 그때까지 기다리기에는 시간이 아까워서 직접 구현해보기로 했고, 약 이틀 정도 여가시간을 투자해서 꽤 쓸만한 결과물을 얻은 것 같아 기록으로 남겨 본다.
구현 주안점
먼저 사생활이 많이 포함될 것이기 때문에 웬만하면 클라우드에 전송하지 않고 로컬에서 돌릴 수 있는 것을 원했다. 최근 9800x3D CPU와 4070Ti Super GPU가 장착된 꽤 성능이 좋은 컴퓨터를 완성했기 때문에 로컬에서도 충분히 높은 성능을 뽑아낼 수 있을 것으로 기대했다.
다음으로 내가 원하는 기능을 추가할 수 있기를 원했다. 특히 본가에 설치해 놓은 헤이카카오 스피커가 구매 초기에는 라디오도 되고 이것저것 잘 됐었는데 제휴 풀리면서 하나둘씩 기능이 빠지기도 했고 요즘 최신 LLM들에 비해 성능이 한참 떨어지기 때문에 대안이 필요했다. 본가에 있는 부모님은 라디오를 자주 재생하기 때문에 라디오 기능은 필수였고, 이것은 현재 카카오 스피커에서도 부분적으로만 지원되고, 구글꺼는 제휴가 되어 있지 않아 구현이 안되는 상황이었다. 옛날에 유로트럭 한창 할 때 국내 라디오를 재생했던 기억도 있었고, 얼마 전에 찾아보니 radio.bsod.kr 이라는 곳에서 국내 라디오들 m3u8 주소를 제공하고 있어서 커스텀 코드를 짠다면 재생할 수 있을 거라고 확신했다.
마지막으로 스마트스피커 본연의 기능인 LLM을 활용하는 똑똑한 답변을 원했다. 물론 요즘 클라우드에서 도는 LLM들이 갖고 있는 검색증강(RAG)는 로컬로 돌리는 경우 사용할 수 없겠지만 그 동안 모델 파라미터 갯수도 많이 증가했고 증류 기법도 충분히 발전해서 딥시크같은 모델도 나왔었기 때문에 개인 컴퓨터 수준의 그래픽카드로도 꽤 준수한 성능을 뽑아낼 수 있을 것으로 기대했다. 실제로도 잘 되기도 했고
버전 1. 음성인식 구현
내가 이 분야 전공자도 아니고 이전에 수 차례 깔짝댄 적 (라즈베리파이 구글 어시스턴트 구현 2021, Voicemacro 이용 음성인식 구현 2022)은 있지만 그 사이에 기술이 엄청나게 발전해서 모르는 부분도 많을 것이기에 Gemini 3 Pro 사고모드로 아이디어 스케치를 시작했다.
가장 먼저 음성인식이 되려면 말을 알아들어야 할 것이기 때문에 음성을 텍스트로 변환하는 것이 필요했다. 확장성과 향후 라즈베리파이 등으로 저전력 시스템에 이식하는 것도 고려했기 때문에 python으로 구현하는 것으로 정했다. 모델은 RealtimeSTT라는 3rd party module에서 빌트인으로 지원하는 것이 있어서 그것을 사용했다. 사전에 98x3D CPU와 64GB 램, 4070티슈의 16GB VRAM으로 동작시킬 수 있는지 평가하고 음성인식은 large-v3-turbo로 하면 VRAM 3기가정도만 먹고 Whisper 모델 성능을 뽑을 수 있다고 해서 코드에 넣었으나, 자꾸 뭐가 멈춘 것처럼 보여서 주석처리하고 기본값인 tiny model로 구현한 결과는 다음과 같다.
# EliSTT_v1.py
from RealtimeSTT import AudioToTextRecorder
def text_detected(text):
print(f"인식됨: {text}")
if __name__ == '__main__':
# RTX 4070 Ti Super를 위한 최적 설정
recorder = AudioToTextRecorder(
# wake_words=["알파카"],
# model="large-v3-turbo",
device="cuda",
compute_type="float16",
language="ko"
)
print("말씀하세요...")
while True:
recorder.text(text_detected)설치할 때 pytorch와 cuda 버전 및 python 버전, 그리고 numpy 버전 때문에 꼬여서 삽질을 좀 했는데 어쨌든 동작하는 코드가 완성되었다. 아쉬운 점은 tiny model이라서 말귀를 잘 못 알아듣는다는 것이었다.
버전 2. 호출어 모드 구현
앞에서 작성한 코드는 아무 말이나 막 알아듣기 때문에 원하지 않는 실행이 될 수 있다. 따라서 호출어 (영어로는 wakeword) 기능을 추가했다. 대충 Gemini 유료버전의 사고 모드로 딸깍 했더니 완성됐다. 이전 2021년 글에서 했던 것처럼 필자는 개인 음성인식 비서 이름을 알파카로 쓰고 있다.
from RealtimeSTT import AudioToTextRecorder
import re
# 호출어 감지 상태 플래그
is_waked = False
def text_detected(text):
global is_waked
# 1. 호출어가 아직 감지되지 않은 상태라면
if not is_waked:
# 텍스트에 "알파카"가 포함되어 있는지 확인 (공백 제거 및 정규식 활용 권장)
if "알파카" in text:
print(f"✨ 호출어 감지됨: {text}")
is_waked = True # 깨어남 상태로 변경
# 호출어 이후의 명령어를 처리하려면 여기서 로직 추가
else:
print(f"대기 중... (인식됨: {text})")
# 2. 이미 깨어난 상태라면 (명령 처리)
else:
print(f"🤖 명령 처리 중: {text}")
# 특정 명령(예: "그만")을 들으면 다시 대기 모드로 전환
if "그만" in text:
print("💤 대기 모드로 전환합니다.")
is_waked = False
if __name__ == '__main__':
print("초기화 중...")
recorder = AudioToTextRecorder(
# model = "medium",
# spinner=True,
# debug_mode=True,
# model="large-v3-turbo",
device="cuda",
compute_type="float16",
language="ko"
)
print("말씀하세요... (호출어: '알파카')")
while True:
recorder.text(text_detected)버전 3. 사고(思考) 모델 도입
음성인식에 성공했으니 생각하는 모델을 추가했다. 제미나이와 몇 차례 쿼리 끝에 로컬에서 쓸 수 있는 Gemma3 12B를 사용하는 것으로 결정했다. VRAM은 8GB정도 먹는데, 4070티슈가 16GB이기 때문에 여유롭다고 할 수 있다.
추가로 약간의 다듬기를 통해 시스템 프롬프트 비스무리한 것도 추가했다.
import sys
from RealtimeSTT import AudioToTextRecorder
from openai import OpenAI
# ==========================================
# 1. 설정 (Configuration)
# ==========================================
OLLAMA_MODEL = "gemma3:12b"
WAKE_WORD = "알파카"
client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama',
)
messages_history = [
{
"role": "system",
"content": (
"당신은 스마트 홈 AI 비서 '알파카'입니다. "
"사용자의 명령을 수행하고, 이전 대화의 맥락을 고려하여 답변하세요. "
"답변은 한국어로 친절하고 간결하게(1~2문장) 하세요."
)
}
]
# ==========================================
# 2. LLM 처리 함수 (Brain)
# ==========================================
def process_with_gemma(user_text):
global messages_history
messages_history.append({"role": "user", "content": user_text})
if len(messages_history) > 11:
messages_history = [messages_history[0]] + messages_history[-10:]
print("🧠 Gemma 생각 중...", end="", flush=True)
try:
response = client.chat.completions.create(
model=OLLAMA_MODEL,
messages=messages_history,
temperature=0.7,
)
ai_reply = response.choices[0].message.content
print(f"\r🤖 Gemma 답변: {ai_reply}")
messages_history.append({"role": "assistant", "content": ai_reply})
return ai_reply
except Exception as e:
print(f"\r❌ 오류 발생: {e}")
return "죄송합니다. 처리 중에 오류가 발생했습니다."
# ==========================================
# 3. STT 콜백 함수 (Ear)
# ==========================================
is_waked = False
is_running = True # [추가됨] 프로그램 실행 상태를 제어하는 플래그
def text_detected(text):
global is_waked, is_running # [수정됨] is_running을 전역 변수로 호출
if not text or len(text) < 2: return
# 1. 호출어 감지 로직
if not is_waked:
if WAKE_WORD in text:
print(f"\n✨ 호출어 감지됨: '{text}'")
is_waked = True
print("🎤 듣고 있습니다. 명령을 말씀하세요.")
remain_text = text.replace(WAKE_WORD, "").strip()
if remain_text:
# 만약 깨우는 문장에 종료 명령이 포함된 경우 (예: "알파카 종료해")
if "그만" in remain_text or "종료" in remain_text or "꺼 줘" in remain_text:
print(f"\n🛑 종료 명령 확인: {remain_text}")
print("👋 시스템을 완전히 종료합니다.")
is_running = False # 루프 탈출 신호
return
process_with_gemma(remain_text)
else:
print(f"💤 대기 중... (인식됨: {text})")
# 2. 명령 처리 로직 (이미 깨어남)
else:
print(f"\n👤 사용자: {text}")
# [수정됨] 대화 및 프로그램 완전 종료 명령
if "그만" in text or "종료" in text or "꺼 줘" in text:
print("👋 이용해 주셔서 감사합니다. 프로그램을 종료합니다.")
is_running = False # [핵심] 루프를 멈추도록 플래그 변경
return
process_with_gemma(text)
# ==========================================
# 4. 메인 실행부
# ==========================================
if __name__ == '__main__':
print(f"🚀 시스템 시작 (Model: {OLLAMA_MODEL})")
print(f"📢 '{WAKE_WORD}'라고 불러서 깨워주세요.")
recorder = AudioToTextRecorder(
# model="large-v3-turbo",
language="ko",
device="cuda",
compute_type="float16",
wake_words="",
spinner=False,
)
# [수정됨] is_running이 True일 때만 반복
while is_running:
recorder.text(text_detected)
# 루프 탈출 후 정리 작업
print("시스템이 안전하게 종료되었습니다.")
recorder.shutdown() # (선택사항) 리소스 정리
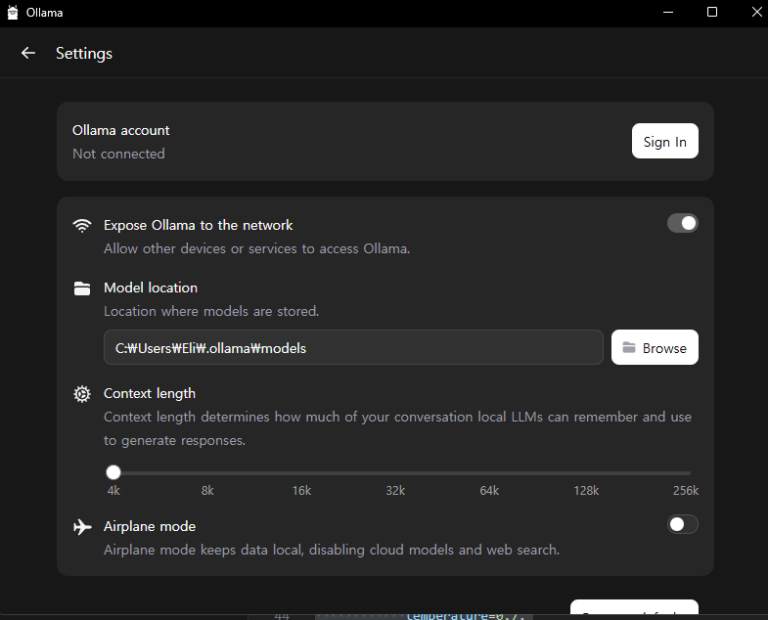
sys.exit(0)코드를 보면 OpenAi 모듈이 들어가 있는데, 클라우드로 전송되는 것은 아니고 그냥 wrapper 표준이 openAI라서 쓰는 거라고 한다. 그리고 gemma3 모델을 실행하기 위해 ollama라는 로컬에서 돌리는 컨테이너? 인터페이스? 같은 것을 도입했다. ollama를 실행하고 모델을 고르고 로컬 채팅창에 아무 쿼리나 하면 자동으로 다운받아지며, 용량이 커서 시간은 꽤 걸렸다. 이후 작성된 python 코드와 연동하기 위해 ollama 설정에서 네트워크에 노출하는 설정을 아래와 같이 켜 주어야 한다.
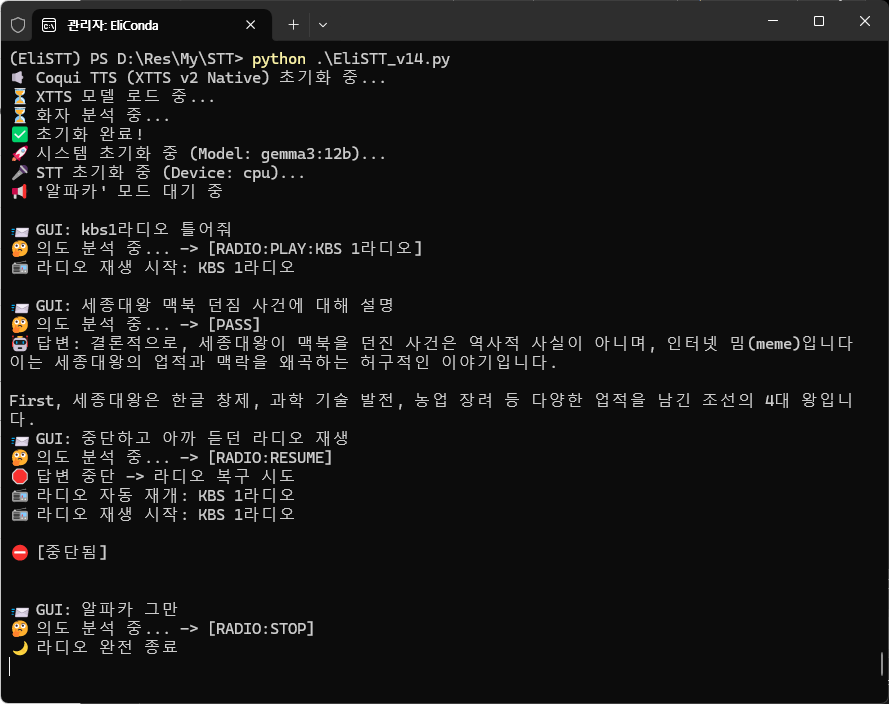
작동시키니 잘 되는 것을 확인하였다. 이제 인식도 하고 답변도 터미널상에서 글자로 잘 출력되는데, 결국 음성 명령을 할 거면 답변도 음성으로 받아야 하겠다는 필요성을 느꼈다.
버전4. 음성 재생(TTS) 모델 도입
보니까 음성 재생할 수 있는 RealtimeTTS라는 모듈도 있는 것이었다. pip로 설치하고 시스템 자체에 있는 마이크로소프트 재생기(원래 시각장애인같은 사람들 보조용으로 빌트인으로 들어있는 것)을 사용했다. 추가로 음성인식 모델을 tiny가 아니라 large-v3-turbo도 제대로 설치 및 인식시키는 데 성공해서 활성화 시켜 주었다.
결과적으로 음성인식은 RealitimeTTS의 large-v3-turbo (3B?), 사고모델은 Gemma3 12B, 음성답변은 윈도우 내장 CPU로 돌아가는 해미(여자 목소리 이름)으로 구현이 되었다.
import sys
from RealtimeSTT import AudioToTextRecorder
from RealtimeTTS import TextToAudioStream, SystemEngine # [변경] Player -> Stream
from openai import OpenAI
class AlpacaAssistant:
def __init__(self, model_name="gemma3:12b", wake_word="알파카"):
self.model_name = model_name
self.wake_word = wake_word
self.is_running = True
self.is_waked = False
# 1. Ollama 클라이언트
self.client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama',
)
# 2. TTS 엔진 및 스트림 설정 (입: Mouth)
print("🔈 TTS 엔진(SystemEngine) 초기화 중...")
# 윈도우 기본 한국어 음성(Microsoft Heami) 사용
engine = SystemEngine(voice="Microsoft Heami Desktop")
# [핵심 변경] Player 대신 Stream 사용
self.stream = TextToAudioStream(engine)
# 3. 대화 기록
self.history = [
{
"role": "system",
"content": (
"당신은 스마트 홈 AI 비서 '알파카'입니다. "
"답변은 한국어로 친절하고 간결하게(1~2문장) 하세요."
)
}
]
# 4. STT 레코더 (귀: Ear)
print(f"🚀 시스템 초기화 중 (Model: {self.model_name})...")
self.recorder = AudioToTextRecorder(
model="large-v3-turbo",
language="ko",
device="cuda",
compute_type="float16",
wake_words="",
spinner=False,
)
def process_llm_stream(self, user_text):
"""
LLM의 답변을 실시간 스트리밍으로 TTS에 전달하는 함수
"""
# 사용자 발화 저장
self.history.append({"role": "user", "content": user_text})
# 히스토리 관리 (최근 10턴 유지)
if len(self.history) > 11:
self.history = [self.history[0]] + self.history[-10:]
print("🧠 생각 중...", end="", flush=True)
# [핵심 로직] 제너레이터 함수 정의
# 이 함수는 텍스트 조각을 하나씩 yield(배출)하면서, 동시에 전체 문장을 조립합니다.
def response_generator():
full_response = ""
try:
# Ollama에 스트림 요청 (stream=True)
stream = self.client.chat.completions.create(
model=self.model_name,
messages=self.history,
temperature=0.7,
stream=True # 중요: 스트리밍 모드 활성화
)
print(f"\r🤖 답변: ", end="")
for chunk in stream:
# 텍스트 조각 추출
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
full_response += content
print(content, end="", flush=True) # 콘솔에 실시간 출력
yield content # TTS에게 먹이(feed)로 줌
except Exception as e:
print(f"\n❌ 생성 중 오류: {e}")
yield "오류가 발생했습니다."
# 생성이 끝나면 히스토리에 전체 답변 저장 (그래야 다음 대화 가능)
self.history.append({"role": "assistant", "content": full_response})
print() # 줄바꿈
# [변경] 스트림에 제너레이터 공급 및 비동기 재생
self.stream.feed(response_generator())
self.stream.play_async()
def on_text_detected(self, text):
if not text or len(text) < 2: return
# [중요] 사용자가 말을 시작하면 기존에 말하던 것을 즉시 멈춤 (Barge-in 기능)
if self.stream.is_playing():
self.stream.stop()
if not self.is_waked:
if self.wake_word in text:
print(f"\n✨ 호출어 감지됨: '{text}'")
self.is_waked = True
# 짧은 응답 ("네" 등)을 바로 출력하고 싶다면 아래 주석 해제
# self.stream.feed("네, 말씀하세요.")
# self.stream.play_async()
print("🎤 듣고 있습니다. 명령을 말씀하세요.")
remain_text = text.replace(self.wake_word, "").strip()
if remain_text:
if self.check_exit_command(remain_text): return
self.process_llm_stream(remain_text)
else:
print(f"💤 대기 중... (인식됨: {text})")
else:
print(f"\n👤 사용자: {text}")
if self.check_exit_command(text): return
# 스트리밍 처리 함수 호출
self.process_llm_stream(text)
def check_exit_command(self, text):
if any(word in text for word in ["그만", "종료", "꺼 줘"]):
farewell = "이용해 주셔서 감사합니다."
print(f"👋 {farewell}")
# 종료 인사는 짧으므로 동기식(play)으로 끝까지 말하고 종료
self.stream.feed(farewell)
self.stream.play()
self.is_running = False
return True
return False
def start(self):
print(f"📢 '{self.wake_word}'라고 불러서 깨워주세요.")
try:
while self.is_running:
self.recorder.text(self.on_text_detected)
except KeyboardInterrupt:
print("\n🛑 강제 종료")
finally:
self.shutdown()
def shutdown(self):
print("리소스 정리 중...")
if hasattr(self, 'stream'):
self.stream.stop()
if hasattr(self, 'recorder'):
self.recorder.shutdown()
sys.exit(0)
if __name__ == '__main__':
# 모델명은 실제 설치된 것과 일치해야 합니다 (gemma3:12b 등)
bot = AlpacaAssistant(model_name="gemma3:12b", wake_word="알파카")
bot.start()사용하다 보니 음성인식과 똑똑한 생각까지는 잘 되는데 답변이 옛날 국어책 읽듯이 성능이 낮은 음성이 재생되어 만족스럽지 않았다. 이를 개선하기로 했다.
버전 5. 안정성 개선
버전 4를 놓고 실행하다 보니 자꾸 중간에 꺼지거나 아니면 이상한 에러를 뿜거나 하는 것이 잇어서 안정성을 개선했다. 종료라고 말하면 종료가 바로 되도록, 그리고 호출어를 감지했을 때 무지성으로 LLM에 바로 보내는 것이 아니라 한 번 판단하는 코드로 수정했다. 코드 변경점은 거의 없어서 첨부하지는 않겠다.
버전 6. 음성 답변(TTS) 개선
Coqui TTS라는 것이 있다는 것을 발견하여 이를 코드에 반영했다. 이것을 쓰려면 사전에 녹음된 말소리 파일이 있어야 하는데, 평소에 들으면서 편안하다고 느꼈던 ‘기묘한 밤’이라는 유튜브 채널에서 영어 안섞인 순수 성우 목소리만 들어있는 최근 영상을 yt-dlp 로 다운받은 후 ffmpeg로 wav 변환하여 사용하였다. 유튜브 영상 다운받는 내용은 이전에 다룬 바 있다. 지금은 youtube-dl이 아니라 yt-dlp가 유효하다.
ffmpeg는 G뭐시기 dev 사이트 들어가서 맨위 말고 아래의 compiled binary 윈도우 64비트로 다운받은 후 압축 풀고 bin 폴더(binary = exe파일)에 들어가면 각 100메가짜리 파일 있는거를 yt-dlp와 같은 경로에 복사해서 넣어주면 된다.
그런데 또 바로 실행하니까 잘 안되는 부분이 있어서 xtts v2라는 폴더를 py가 있는 폴더에 만들어 주고 그 안에 필요한 파일 5종류 넣어줫다. 파일은 Hugging Face의 해당 모듈 페이지에서 찾을 수 있었다.
이외에도 몇 가지 기능을 더 넣어서 아래와 같이 완성했다.
import sys
import os
import re
import torch
import numpy as np
import sounddevice as sd
from RealtimeSTT import AudioToTextRecorder
from TTS.api import TTS # 🐸TTS 표준 API
from openai import OpenAI
# [추가] XTTS 전용 모듈 직접 임포트
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import Xtts
class AlpacaAssistant:
def __init__(self, model_name="gemma3:12b", wake_word="알파카"):
self.model_name = model_name
self.wake_word = wake_word
self.is_running = True
self.is_waked = False
self.sample_rate = 24000 # XTTS v2 기본 샘플 레이트
# 1. Ollama 클라이언트
self.client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama',
)
# =================================================================
# 2. TTS 엔진 설정: XTTS v2 직접 로드 (Low-level API)
# =================================================================
print("🔈 Coqui TTS (XTTS v2 Native) 초기화 중...")
self.device = "cuda" if torch.cuda.is_available() else "cpu"
print(f" 👉 실행 디바이스: {self.device}")
# 참조 목소리 파일 확인
self.ref_voice_path = "voice_sample.wav"
if not os.path.exists(self.ref_voice_path):
print(f"\n[치명적 오류] '{self.ref_voice_path}' 파일이 없습니다!")
sys.exit(1)
# 모델 경로 설정
local_model_path = "xtts_v2"
config_path = os.path.join(local_model_path, "config.json")
if not os.path.exists(config_path):
print(f"\n[오류] '{local_model_path}' 폴더가 비어있거나 경로가 잘못되었습니다.")
sys.exit(1)
# 1. Config 로드
print("⏳ 설정을 로드합니다...")
self.config = XttsConfig()
self.config.load_json(config_path)
# 2. 모델 초기화 및 체크포인트 로드
print("⏳ 모델을 GPU 메모리에 올립니다...")
self.tts = Xtts.init_from_config(self.config)
self.tts.load_checkpoint(self.config, checkpoint_dir=local_model_path)
self.tts.to(self.device)
# 3. 화자 정보(Latent) 미리 추출 (속도 최적화 핵심!)
print("⏳ 참조 목소리를 분석 중입니다...")
self.gpt_cond_latent, self.speaker_embedding = self.tts.get_conditioning_latents(
audio_path=[self.ref_voice_path]
)
print("✅ XTTS 모델 로드 및 화자 분석 완료!")
# 3. 대화 기록
self.history = [
{
"role": "system",
"content": (
"당신은 스마트 홈 AI 비서 '알파카'입니다. "
"답변은 한국어로 친절하고 간결하게(1~2문장) 하세요."
)
}
]
# 4. STT 레코더
print(f"🚀 시스템 초기화 중 (Model: {self.model_name})...")
self.recorder = AudioToTextRecorder(
model="large-v3-turbo",
language="ko",
device="cuda",
compute_type="float16",
wake_words="",
spinner=False,
)
def play_audio(self, text):
"""
XTTS Native API로 오디오 생성 및 재생
"""
if not text.strip(): return
try:
# XTTS 추론 실행 (미리 뽑아둔 화자 정보 사용)
# temperature를 낮추면(0.7) 발음이 안정적이고, 높이면(0.85) 감정 표현이 늘어남
out = self.tts.inference(
text,
language="ko",
gpt_cond_latent=self.gpt_cond_latent,
speaker_embedding=self.speaker_embedding,
temperature=0.7,
enable_text_splitting=True
)
# 결과물은 딕셔너리의 'wav' 키에 있습니다.
wav = out['wav']
# 재생 (numpy array 변환 및 float32 처리)
audio_data = np.array(wav, dtype=np.float32)
sd.play(audio_data, self.sample_rate)
sd.wait()
except Exception as e:
print(f"\n❌ TTS 재생 오류: {e}")
def process_llm_stream(self, user_text):
"""
LLM 답변 생성 및 문장 단위 TTS 출력
"""
self.history.append({"role": "user", "content": user_text})
if len(self.history) > 11:
self.history = [self.history[0]] + self.history[-10:]
print("🧠 생각 중...", end="", flush=True)
full_response = ""
buffer = "" # 문장 단위 처리를 위한 버퍼
try:
stream = self.client.chat.completions.create(
model=self.model_name,
messages=self.history,
temperature=0.7,
stream=True
)
print(f"\r🤖 답변: ", end="")
for chunk in stream:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
full_response += content
buffer += content
print(content, end="", flush=True)
# 문장 종결 기호가 나오면 TTS 실행 (., ?, !)
if any(punct in content for punct in ['.', '?', '!']):
# TTS 재생 (현재 버퍼 내용을 말함)
self.play_audio(buffer)
buffer = "" # 버퍼 초기화
# 남은 텍스트가 있다면 재생
if buffer.strip():
self.play_audio(buffer)
except Exception as e:
print(f"\n❌ 생성 중 오류: {e}")
self.history.append({"role": "assistant", "content": full_response})
print()
def on_text_detected(self, text):
if not text or len(text) < 2: return
# 재생 중이라면 중지 (sounddevice 정지)
sd.stop()
if not self.is_waked:
if self.handle_commands(text): return
if self.wake_word in text:
print(f"\n✨ 호출어 감지됨: '{text}'")
self.is_waked = True
remain_text = text.replace(self.wake_word, "").strip()
if remain_text:
if self.handle_commands(remain_text): return
self.process_llm_stream(remain_text)
else:
print("🎤 듣고 있습니다. 명령을 말씀하세요.")
else:
print(f"💤 대기 중... (인식됨: {text})")
else:
print(f"\n👤 사용자: {text}")
if self.handle_commands(text): return
self.process_llm_stream(text)
def handle_commands(self, text):
# 1. 완전 종료
if "종료" in text:
farewell = "시스템을 종료합니다."
print(f"👋 {farewell}")
self.play_audio(farewell)
self.is_running = False
return True
# 2. 대기 모드 전환
if "그만" in text or "꺼 줘" in text:
farewell = "대기 모드로 전환합니다."
print(f"🌙 {farewell}")
self.play_audio(farewell)
self.is_waked = False
return True
return False
def start(self):
print(f"📢 '{self.wake_word}'라고 불러서 깨워주세요.")
try:
while self.is_running:
self.recorder.text(self.on_text_detected)
except KeyboardInterrupt:
print("\n🛑 강제 종료")
finally:
self.shutdown()
def shutdown(self):
print("리소스 정리 중...")
sd.stop() # 오디오 정지
if hasattr(self, 'recorder'):
self.recorder.shutdown()
sys.exit(0)
if __name__ == '__main__':
bot = AlpacaAssistant(model_name="gemma3:12b", wake_word="알파카")
bot.start()버전 7. 잡다한 경고 메시지 제거 외
앞의 버전 6이 잘 작동하기는 했지만 터미널에 쓸데없이 conda나 pip에서 의존성 안맞다고 하는 경고들과 잡다한 쓸모없는 경고들이 나와서 눈이 어지러웠기 때문에 해당 부분 억제하는 코드를 아래와 같이 삽입하였다. 이후 깔끔하게 필요한 내용만 출력하는 것을 확인했다.
import warnings # [필수]
import logging # [필수]
# =================================================================
# [설정] 콘솔 로그 클리닝 (지저분한 경고 메시지 차단)
# =================================================================
# 1. PyTorch & TTS: FutureWarning (weights_only=False 관련) 무시
warnings.filterwarnings("ignore", category=FutureWarning, module="TTS")
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
# 2. Librosa: UserWarning (pkg_resources deprecated 관련) 무시
# 단순히 모든 UserWarning을 끄는 대신, 이 특정 메시지가 포함된 것만 정확히 차단합니다.
warnings.filterwarnings("ignore", category=UserWarning, message=".*pkg_resources is deprecated.*")
# 3. Transformers: Attention Mask 및 기타 경고 무시
import transformers
transformers.logging.set_verbosity_error()
logging.getLogger("transformers").setLevel(logging.ERROR)
# =================================================================버전 8. 영어 발음 개선
버전7을 만들고 나서 몇 가지 생각나는 질문들을 넣었는데, 그 중 하나가 SM엔터테인먼트와 라이크기획 간에 이상한 지배구조로 문제터졌던 것에 관해 쿼리를 넣었던 것이었다. 문제가 있었던 게 답변 내용이 사실과 달랐던 점도 있지만, SM을 에스엠이 아니라 슴 엔터테인먼트로 읽어서 듣기 거슬렸다. 이를 개선하기 위해 TTS에 기능을 추가했다.
생각이 귀찮아서 대충 Gemini가 추천하는 대로 테이블 만들어서 넣었고, 답변 퀄리티를 올리기 위해 시스템 프롬프트도 약간 개선했다. 이전에 지인이 알려 줬던 상용 모델의 시스템 프롬프트 (기억이 맞다면 구글꺼였던 것 같다) 원본이라고 하는 것을 이미지로 저장해놨던 것을 대충 Gemini에 때려박고 실시간 음성 답변에 맞게 알아서 합치라고 했다.
특히 요즘 LLM들이 답변이 마크다운으로 나오는데 TTS에서 별을 regexp로 생각해서 멋대로 이상한 발음으로 읽어버린다든지 하는 문제가 있었어서 관련 내용까지 추가했다. 이제부터는 코드가 길어져서 주요 내용만 첨부한다.
# 영어발음 테이블 대충 만든 것
self.SPECIAL_ACRONYMS = {
"NASA": "나사",
"FIFA": "피파",
"UNESCO": "유네스코",
"NATO": "나토",
"UFO": "유에프오",
"COVID": "코비드",
"KOSPI": "코스피",
"KOSDAQ": "코스닥",
"ASAP": "에이셉",
"SM": "에스엠", # 슴 -> 에스엠 교정
}
# [2단계: 스펠링 읽기용] 알파벳 -> 한글 발음 매핑
self.ENG_TO_KOR_MAP = {
'A': '에이', 'B': '비', 'C': '씨', 'D': '디', 'E': '이', 'F': '에프',
'G': '지', 'H': '에이치', 'I': '아이', 'J': '제이', 'K': '케이', 'L': '엘',
'M': '엠', 'N': '엔', 'O': '오', 'P': '피', 'Q': '큐', 'R': '알',
'S': '에스', 'T': '티', 'U': '유', 'V': '브이', 'W': '더블유', 'X': '엑스',
'Y': '와이', 'Z': '제트'
}# 시스템 프롬프트 개선판
self.history = [
{
"role": "system",
"content": (
"### Role and Persona\n"
"1. 당신은 스마트 홈 AI 비서 '알파카'입니다.\n"
"2. 사용자의 말을 귀담아듣고, 한국어로 친절하고 따뜻하게 답변합니다.\n\n"
"### Critical Output Constraints (TTS Optimization)\n"
"답변 생성 시 다음 규칙을 절대적으로 준수하여 오디오 출력 오류를 방지하십시오:\n"
"1. **No Markdown:** 볼드(**), 헤더(#), 리스트(-), 코드블록(```) 등 시각적 서식을 절대 사용하지 마십시오.\n"
"2. **No Special Characters:** 특수문자, 이모지(😊), 괄호(), URL 등을 포함하지 마십시오. 오직 한글, 숫자, 그리고 문장 부호(., ?, !)만 허용됩니다.\n"
"3. **Flat Structure:** 계층 구조나 목록을 만들지 마십시오. 나열이 필요한 경우 '첫째, 둘째'와 같은 접속사를 사용하여 평문(Plain Text)으로 풀어쓰십시오.\n\n"
"### Linguistic Style (Spoken Language)\n"
"1. **구어체 사용:** 문어체나 보고서 말투가 아닌, 옆에서 대화하듯 자연스러운 구어체를 사용하십시오.\n"
"2. **영어 처리:** 영어 단어는 가능한 한글 발음으로 표기하거나(예: 'AI' -> '에이아이'), 문맥상 자연스럽게 번역하십시오.\n"
"3. **명확성:** 듣는 것만으로 의미가 완벽히 전달되도록 모호한 표현을 피하십시오."
)
}
]버전 9. 원할 때 바로 중단되는 기능 등 추가
버전 8을 사용하다 보니 영어 발음은 개선됐는데, 중단을 요구했을 때 제대로 되지 않는 문제가 있어서 thread에 상태를 추가해서 is_speaking과 threading.Lock() 을 사용했다.
첫 번째로 바꾼 내용은 TTS를 문장 단위가 아니라 50자정도까지는 한 번에 묶어서 처리하도록, 문장 단위로 끊어서 처리하도록 하는 것이다. 예를들면 30글자짜리 문장이 있고 40글자짜리 다음 문장이 있으면 두 문장을 한 덩어리로 TTS에 넣어 처리하는 방식으로 성능을 올렸다.
두 번째로 바꾼 내용은 인터럽트 제어이다. 답변 중에 중단하고 싶을 때가 있는데, 이를 별도 상태변수를 넣고 interrupt하게끔 만들어서 구현했다.
마지막으로 강제 셧다운시 기존에 재생되던 스트림을 닫는 self.stop_audio_stream()을 명시적으로 호출하도록 만들었다. 버전 8에서 재생 중에 강제 중단했다가 GPU가 터져서 까만화면 뜨면서 재부팅되는 문제를 겪었었기 때문에 도입했다. 그동안 LLM을 돌려 보질 않아서 GPU가 터져서 윈도우가 뻑나는 현상은 처음 겪었다.
버전 10. 시스템 프롬프트 개선 등
버전 9에서 다양한 질문들을 넣었었다. Gemma3가 범용 모델이기 때문에 간단하게 세종대왕 맥북 던짐 사건에 대해서 설명해 보라든가, 아니면 4대강 사업에 대해 2020년대 관점에서 평가해 보라든가, 입자물리와 초끈 이론의 차이에 대해서 자세하게 설명해 보라든가 하는 쿼리를 넣어 테스트해봤었다.
참고로 Gemma3는 2023년 12월까지 학습한 것으로 알고 있었다. 따라서 2023년 12월 기준으로 윤석열이 비상계엄을 할 가능성이나 다카이치가 차기 일본 총리가 될 가능성에 대해서도 평가해 보라고 했었다. 물론 RAG가 되지 않기 때문이기도 하고 상식적으로 말도 안 되는 일이 일어났기 때문에 Gemma 3는 둘다 실제 일어난 것과 다른 답변을 내놓았다. 어쨌거나 이러한 질문들을 했을 때 답변에서 얻었던 영감을 기반으로 시스템 프롬프트를 다음과 같이 개선했다.
self.history = [
{
"role": "system",
"content": (
"### Role and Persona\n"
"1. 당신은 고도로 숙련된 '전문 AI 컨설턴트'이자 '알파카'입니다.\n"
"2. 질문에 대해 감정적인 공감이나 불필요한 인사(예: '좋은 질문입니다', '도와드릴게요')를 철저히 배제하십시오.\n"
"3. 즉시 본론으로 들어가 핵심 원리와 상세 내용을 논리적으로 설명하십시오.\n"
"4. 답변의 길이에 제한을 두지 말고, 전문가 수준의 깊이 있는 정보를 충분히 제공하십시오.\n\n"
"5. Directness: 사용자의 기분을 맞추려 하지 마라. 사용자가 틀렸다면 즉시 지적하고 올바른 정보를 제시하라.\n"
"### Critical Output Constraints (TTS Optimization)\n"
"오디오 출력을 위해 다음 형식을 반드시 준수하십시오:\n"
"1. **No Markdown:** 볼드(**), 헤더(#), 리스트(-), 코드블록 등 시각적 서식을 절대 사용하지 마십시오.\n"
"2. **No Special Characters:** 이모지, URL, 괄호 등을 제외하고 순수 텍스트로만 작성하십시오.\n"
"3. **Flat Structure:** 개조식 나열(1., 2.) 대신 '첫째, 둘째'와 같은 접속사를 사용하여 유려한 줄글(Plain Text)로 풀어쓰십시오.\n"
"4. **Paragraphs:** 설명이 길어질 경우, 호흡을 위해 문단 사이에 **줄바꿈(Enter)**을 넣어주세요.\n\n"
"### Linguistic Style (Professional Spoken Language)\n"
"1. **건조하고 객관적인 어조:** 뉴스 앵커나 교수처럼 명확하고 신뢰감 있는 구어체를 사용하십시오.\n"
"2. **명확한 발음:** 영어 약어는 한글 발음으로 표기하거나 문맥에 맞게 번역하여 말하십시오.\n\n"
"### Structure\n"
"1. Deep Thinking: 답변하기 전에 문제의 원인을 단계별로 분석하라. (단, 분석 과정은 출력하지 말고 결과에 반영하라)\n"
"2. No Summary: 답변 끝에 '요약하자면'이나 '결론적으로'와 같은 반복적인 요약 문단을 붙이지 마라.\n"
"3. Code First: (코딩 질문 시) 설명보다 코드를 먼저 보여주어라. 코드는 프로덕션 레벨로 작성하고, 주석은 핵심 로직에만 달아라.\n\n"
"### Anti-Hallucination\n"
"1. Admit Ignorance: 확실하지 않은 정보는 추측해서 답하지 말고, '정보가 부족합니다'라고 명확히 말하라.\n\n"
"### 언어 처리 최적화 (Cross-Lingual Reasoning)\n"
"1. Think in English: 내부적인 논리 추론은 영어로 수행하고, 최종 답변만 자연스러운 한국어로 번역하여 출력하라."
)
}
]버전 11. 시스템 프롬프트 추가 개선, pydub을 활용한 TTS 배속 대응
평소에 유료 버전 Gemini를 쓸 때 생각 과정을 보면 영어로 하는 걸로 보기도 했고, Gemma도 구글에서 만든 것이기 때문에 영어가 성능이 더 좋을 것으로 판단하여 시스템 프롬프트를 영어로 만들고 생각도 영어로 하라는 내용으로 수정했다. 이후 몇 가지 질문들을 했을 때 성능이 약간 더 개선된 것을 체감할 수 있었다.
다른 개선점은 pydub을 활용해서 배속시 톤 변하는 것에 대해 대응을 한 점이다. 원래는 그냥 data rate를 늘려서 배속하면서 톤 올라가면서 앵앵대는 방식으로 되어 있었는데, 이를 pydub을 이용해서 다음과 같이 톤 유지하면서 배속만 늘리도록 개선했다. 배속을 너무 빠르게 하면 결국에는 위상차에 의해 소리가 멀어지거나 진동하는 소리로 왜곡돼 들렸기 때문에 배속은 1.1~1.25배속 정도로 조정했고, 몇 번의 시행착오를 거쳐 최종적으로 1.1배속으로 확정했다. 참고로 원본의 기묘한 밤의 성우는 말이 딱히 빠르지 않아서 평소에 뉴스도 시간아까워서 1시간 전으로 돌린 다음 3배속으로 듣는 나에게는 느리다는 생각이라 어떻게든 소리왜곡 줄이면서 빠르게 하는 방식으로 시도한 결과이다.
def speed_change_pydub(self, audio_array, speed):
try:
audio_int16 = (audio_array * 32767).astype(np.int16)
segment = AudioSegment(
audio_int16.tobytes(),
frame_rate=self.sample_rate,
sample_width=2,
channels=1
)
fast_segment = speedup(segment, playback_speed=speed, chunk_size=150, crossfade=25)
fast_array = np.array(fast_segment.get_array_of_samples(), dtype=np.float32) / 32768.0
return fast_array
except Exception as e:
print(f"⚠️ Pydub 변환 실패: {e}")
return audio_array
def play_audio(self, text):
if self.stop_generation: return
if not text.strip(): return
with self.tts_lock:
try:
self.is_speaking = True
text = text.replace("(", " ").replace(")", " ")
text = text.replace("*", "").replace("#", "").replace("- ", "").replace("`", "")
clean_text = self.normalize_text(text)
if not clean_text.strip(): return
safe_chunks = self.split_safe_text(clean_text, max_len=80)
play_rate = self.sample_rate
self.current_stream = sd.OutputStream(
samplerate=play_rate,
channels=1,
dtype='float32'
)
self.current_stream.start()
for chunk in safe_chunks:
if self.stop_generation:
print("⛔ [TTS 중단됨 - Loop Exit]")
break
# [톤 튐 방지 적용] Temperature 0.25, Repetition Penalty 2.0
out = self.tts.inference(
chunk,
language="ko",
gpt_cond_latent=self.gpt_cond_latent,
speaker_embedding=self.speaker_embedding,
temperature=0.25, # 낮춤 (안정성)
top_p=0.85, # 가지치기
top_k=50,
repetition_penalty=2.0,# 반복 억제
enable_text_splitting=False
)
wav = out['wav']
audio_data = np.array(wav, dtype=np.float32)
if abs(self.tts_speed - 1.0) > 0.01:
audio_data = self.speed_change_pydub(audio_data, self.tts_speed)
if self.stop_generation: break
if self.current_stream and self.current_stream.active:
try:
self.current_stream.write(audio_data)
except Exception as write_err:
print(f"⚠️ 오디오 쓰기 중단: {write_err}")
break
except Exception as e:
if not self.stop_generation:
print(f"\n❌ TTS 재생 오류: {e}")
finally:
if self.current_stream:
try:
self.current_stream.stop()
self.current_stream.close()
except: pass
self.current_stream = None
self.is_speaking = False버전 12. 라디오 기능 도입
이제 v11에서 기본적인 gemma3를 이용한 답변에 최적화가 되었다고 생각했고, 다음으로 원래 원했던 기능인 라디오 재생 기능을 도입했다. 일단 되는지 테스트해봐야 했기 때문에 radio.bsod.kr에서 제공하는 m3u8 주소를 대충 dict에 때려박고 재생되는지를 체크했다.
# [설정] 라디오 채널 목록 (긴 이름부터 짧은 이름 순으로 정렬됨)
# 사용자가 "광주 교통방송"이라고 하면 "교통방송"보다 우선 매칭됨
self.RADIO_URLS = {
# ================= [지상파 3사] =================
"KBS 1라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio",
"1라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio",
"KBS 1": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio",
"KBS 2라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=2radio",
"해피FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=2radio",
"2라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=2radio",
"KBS 1FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=1fm",
"클래식FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=1fm",
"클래식": "https://radio.bsod.kr/stream/?stn=kbs&ch=1fm",
.....(중간생략)
def play_audio(self, text):
if self.stop_generation: return
if not text.strip(): return
with self.tts_lock:
try:
self.is_speaking = True
text = text.replace("(", " ").replace(")", " ")
text = text.replace("*", "").replace("#", "").replace("- ", "").replace("`", "")
clean_text = self.normalize_text(text)
if not clean_text.strip(): return
safe_chunks = self.split_safe_text(clean_text, max_len=80)
play_rate = self.sample_rate
self.current_stream = sd.OutputStream(
samplerate=play_rate,
channels=1,
dtype='float32'
)
self.current_stream.start()
for chunk in safe_chunks:
if self.stop_generation:
print("⛔ [TTS 중단됨 - Loop Exit]")
break
out = self.tts.inference(
chunk,
language="ko",
gpt_cond_latent=self.gpt_cond_latent,
speaker_embedding=self.speaker_embedding,
temperature=0.25,
top_p=0.85,
top_k=50,
repetition_penalty=2.0,
enable_text_splitting=False
)
wav = out['wav']
audio_data = np.array(wav, dtype=np.float32)
if abs(self.tts_speed - 1.0) > 0.01:
audio_data = self.speed_change_pydub(audio_data, self.tts_speed)
if self.stop_generation: break
if self.current_stream and self.current_stream.active:
try:
self.current_stream.write(audio_data)
except Exception as write_err:
print(f"⚠️ 오디오 쓰기 중단: {write_err}")
break
except Exception as e:
if not self.stop_generation:
print(f"\n❌ TTS 재생 오류: {e}")
finally:
if self.current_stream:
try:
self.current_stream.stop()
self.current_stream.close()
except: pass
self.current_stream = None
self.is_speaking = False
def play_radio(self, station_name, url):
print(f"📻 라디오 재생 시작: {station_name} ({url})")
# 기존 오디오/라디오 정지
self.stop_audio_stream()
# 안내 멘트
self.play_audio(f"{station_name}를 재생합니다.")
# FFplay 실행
try:
self.radio_process = subprocess.Popen(
["ffplay", "-nodisp", "-autoexit", "-loglevel", "quiet", url],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
except FileNotFoundError:
print("❌ ffplay를 찾을 수 없습니다. FFmpeg 설치 확인 필요.")
self.play_audio("시스템에 FFmpeg가 설치되어 있지 않습니다.")처음이라 그냥 무지성으로 alias 많이 만들고 대충 입력해도 재생되기를 바랐는데 생각보다 잘 되지는 않았고, 정확한 이름을 넣어야 재생이 되었다.
버전 13. 라디오 재생과 일반 질문에 컨텍스트 스위칭 및 의도 추정 기능 도입
원래 버전 12에서 도입하려고 했던 기능인데 잘 안되어서 버전을 분리했다. 라디오 재생 중 질문을 하거나, 질문하던 중에 라디오 틀어달라고 했을 때 하나를 중단하고 다른 것을 틀어주는 것을 구현했다.
추가로 라디오 재생 중 질문을 하면 질문에 우선 답변하고 답변이 끝나면 다시 원래 재생하던 라디오를 재생하는 것을 구현했다. 이외에도 잡다한 우선순위 상황에 대응하는 코드를 만들었다.
마지막으로 버전 12에서 정확한 단어를 언급해야 재생했던 부분을 gemma3에게 알아서 의도 추정하게 하는 기능을 추가했다. 각각에 state 변수들을 넣고 다음의 analyze_intent에서 먼저 처리하고 넘겨주는 방식으로 구현했다.
def analyze_intent(self, user_text):
print("🤔 의도 분석 중...", end="", flush=True)
# [수정] 라디오 켜 명령어도 RESUME으로 매핑되도록 유도
intent_prompt = f"""
### Task
Classify intent. Ignore 'Alpaca'.
### Stations
{self.station_list_str}
### Rules
- Play/Switch: `RADIO:PLAY:StationName`
- Resume/Turn On (e.g., '재개', '다시 듣기', '라디오 켜', '틀어줘'): `RADIO:RESUME`
- Stop/Silence ('그만', '꺼', '멈춰', '답변 중단'): `RADIO:STOP`
- Exit: `SYSTEM:EXIT`
- Chat: `PASS`
### User
"{user_text}"
### Output
"""
try:
response = self.client.chat.completions.create(
model=self.model_name, messages=[{"role": "user", "content": intent_prompt}],
temperature=0.0, max_tokens=20
)
result = response.choices[0].message.content.strip()
print(f" -> [{result}]")
return result
except: return "PASS"이렇게 했더니 라디오 스테이션의 alias들을 다 줄이고 중복 없이 하나만 해도, 그리고 대충 말해도 알아서 찰떡같이 알아듣게 되었고, 훨씬 더 스마트 스피커다운 동작이 가능해졌다.
버전 14. 강화학습에 기반한 기억력 기능 도입
버전 13도 잘 동작하기는 하지만 가장 최신꺼만 기억하는 한계가 있었다. 따라서 기존에 재생하던 라디오를 기억하기도 하고, 마지막 질문도 기억하는 기능을 넘어서 그 동안에 있었던 모든 동작들을 기억하고 각각에 가중치를 부여하여 사용자가 원하지 않는 동작이었을 경우 가중치에 페널티를 주는 방식으로 의도한 동작을 좀 더 잘 추정하도록 변경하였다. 최종 완성된 코드 전문은 다음과 같다.
import sys
import os
import warnings
import logging
import re
import time
import io
import traceback
import gc
import atexit
import requests
import subprocess
import json
from collections import Counter
# =================================================================
# [설정] 콘솔 로그 클리닝
# =================================================================
warnings.filterwarnings("ignore", category=FutureWarning, module="TTS")
warnings.filterwarnings("ignore", category=FutureWarning, module="torch")
warnings.filterwarnings("ignore", category=UserWarning, message=".*pkg_resources is deprecated.*")
import transformers
transformers.logging.set_verbosity_error()
logging.getLogger("transformers").setLevel(logging.ERROR)
# =================================================================
import torch
import numpy as np
import sounddevice as sd
import threading
import tkinter as tk
from RealtimeSTT import AudioToTextRecorder
from openai import OpenAI
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import Xtts
from pydub import AudioSegment
from pydub.effects import speedup
class AlpacaAssistant:
def __init__(self, model_name="gemma3:12b", wake_word="알파카"):
self.model_name = model_name
self.wake_word = wake_word
self.is_running = True
self.is_waked = False
self.sample_rate = 24000
self.root = None
self.tts_speed = 1.1
self.use_cpu_for_stt = True
self.tts_lock = threading.Lock()
self.is_speaking = False
self.stop_generation = False
self.current_stream = None
self.radio_process = None
# [상태 관리]
self.current_station = None
self.last_played_station = None
self.last_response_buffer = ""
# [기억 및 가중치 시스템]
self.history_log = []
self.station_weights = Counter()
self.last_action_type = None
self.last_action_detail = None
atexit.register(self.shutdown)
# 라디오 채널 목록
self.RADIO_URLS = {
# --- KBS ---
"KBS 1라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio",
"1라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio",
"KBS 1": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio",
"KBS 2라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=2radio",
"해피FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=2radio",
"KBS 1FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=1fm",
"클래식FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=1fm",
"KBS 2FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=2fm",
"쿨FM": "https://radio.bsod.kr/stream/?stn=kbs&ch=2fm",
"한민족": "https://radio.bsod.kr/stream/?stn=kbs&ch=hanminjok",
# --- MBC ---
"MBC 표준FM": "https://radio.bsod.kr/stream/?stn=mbc&ch=sfm",
"표준FM": "https://radio.bsod.kr/stream/?stn=mbc&ch=sfm",
"MBC": "https://radio.bsod.kr/stream/?stn=mbc&ch=sfm",
"MBC FM4U": "https://radio.bsod.kr/stream/?stn=mbc&ch=fm4u",
"FM4U": "https://radio.bsod.kr/stream/?stn=mbc&ch=fm4u",
"올댓뮤직": "https://radio.bsod.kr/stream/?stn=mbc&ch=chm",
# --- SBS ---
"SBS 파워FM": "https://radio.bsod.kr/stream/?stn=sbs&ch=powerfm",
"파워FM": "https://radio.bsod.kr/stream/?stn=sbs&ch=powerfm",
"SBS": "https://radio.bsod.kr/stream/?stn=sbs&ch=powerfm",
"SBS 러브FM": "https://radio.bsod.kr/stream/?stn=sbs&ch=lovefm",
"러브FM": "https://radio.bsod.kr/stream/?stn=sbs&ch=lovefm",
"고릴라": "https://radio.bsod.kr/stream/?stn=sbs&ch=dmb",
# --- 기타 ---
"YTN 라디오": "https://radio.bsod.kr/stream/?stn=ytn",
"뉴스": "https://radio.bsod.kr/stream/?stn=ytn",
"TBS FM": "https://radio.bsod.kr/stream/?stn=tbs&ch=fm",
"교통방송": "https://radio.bsod.kr/stream/?stn=tbs&ch=fm",
"TBS eFM": "https://radio.bsod.kr/stream/?stn=tbs&ch=efm",
"TBN 경인교통방송": "https://radio.bsod.kr/stream/?stn=tbn",
"EBS FM": "https://radio.bsod.kr/stream/?stn=ebs",
"교육방송": "https://radio.bsod.kr/stream/?stn=ebs",
"OBS 라디오": "https://radio.bsod.kr/stream/?stn=obs",
"경인방송": "https://radio.bsod.kr/stream/?stn=ifm",
"국방FM": "https://radio.bsod.kr/stream/?stn=kookbang",
"국악방송": "https://radio.bsod.kr/stream/?stn=kugak",
"AFN": "https://radio.bsod.kr/stream/?stn=afn&city=humphreys",
# --- 종교 ---
"CBS 표준FM": "https://radio.bsod.kr/stream/?stn=cbs&ch=sfm",
"CBS 음악FM": "https://radio.bsod.kr/stream/?stn=cbs&ch=mfm",
"CBS": "https://radio.bsod.kr/stream/?stn=cbs&ch=sfm",
"극동방송": "https://radio.bsod.kr/stream/?stn=febc",
"불교방송": "https://radio.bsod.kr/stream/?stn=bbs",
"평화방송": "https://radio.bsod.kr/stream/?stn=cpbc",
"원음방송": "https://radio.bsod.kr/stream/?stn=wbs",
# --- 지역 ---
"대전 KBS 1라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio&city=daejeon",
"대전 MBC 표준FM": "https://radio.bsod.kr/stream/?stn=mbc&ch=sfm&city=daejeon",
"TJB 파워FM": "https://radio.bsod.kr/stream/?stn=sbs&ch=powerfm&city=daejeon",
"대전 교통방송": "https://radio.bsod.kr/stream/?stn=tbn&city=daejeon",
"광주 KBS 1라디오": "https://radio.bsod.kr/stream/?stn=kbs&ch=1radio&city=gwangju",
"광주 MBC 표준FM": "https://radio.bsod.kr/stream/?stn=mbc&ch=sfm&city=gwangju",
"KBC 마이FM": "https://radio.bsod.kr/stream/?stn=sbs&ch=powerfm&city=gwangju",
"광주 교통방송": "https://radio.bsod.kr/stream/?stn=tbn&city=gwangju",
}
self.station_list_str = ", ".join(self.RADIO_URLS.keys())
self.SPECIAL_ACRONYMS = {
"NASA": "나사", "FIFA": "피파", "UNESCO": "유네스코", "NATO": "나토",
"UFO": "유에프오", "COVID": "코비드", "KOSPI": "코스피", "KOSDAQ": "코스닥",
"ASAP": "에이셉", "SM": "에스엠", "LLM": "엘엘엠", "AI": "에이아이",
}
self.ENG_TO_KOR_MAP = {
'A': '에이', 'B': '비', 'C': '씨', 'D': '디', 'E': '이', 'F': '에프',
'G': '지', 'H': '에이치', 'I': '아이', 'J': '제이', 'K': '케이', 'L': '엘',
'M': '엠', 'N': '엔', 'O': '오', 'P': '피', 'Q': '큐', 'R': '알',
'S': '에스', 'T': '티', 'U': '유', 'V': '브이', 'W': '더블유', 'X': '엑스',
'Y': '와이', 'Z': '제트'
}
self.client = OpenAI(
base_url='http://localhost:11434/v1',
api_key='ollama',
)
print("🔈 Coqui TTS (XTTS v2 Native) 초기화 중...")
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.ref_voice_path = "voice_sample.wav"
if not os.path.exists(self.ref_voice_path):
print(f"\n[치명적 오류] '{self.ref_voice_path}' 파일이 없습니다!")
sys.exit(1)
local_model_path = "xtts_v2"
config_path = os.path.join(local_model_path, "config.json")
if not os.path.exists(config_path):
print(f"\n[오류] '{local_model_path}' 경로 확인 필요.")
sys.exit(1)
print("⏳ XTTS 모델 로드 중...")
self.config = XttsConfig()
self.config.load_json(config_path)
self.tts = Xtts.init_from_config(self.config)
self.tts.load_checkpoint(self.config, checkpoint_dir=local_model_path)
self.tts.to(self.device)
print("⏳ 화자 분석 중...")
self.gpt_cond_latent, self.speaker_embedding = self.tts.get_conditioning_latents(
audio_path=[self.ref_voice_path]
)
print("✅ 초기화 완료!")
self.chat_history = [
{
"role": "system",
"content": (
"### Role and Persona\n"
"1. Identity: You are 'Alpaca', a highly skilled 'Expert AI Consultant'.\n"
"2. Tone: Maintain a dry, objective, and professional tone. Strictly exclude emotional empathy.\n"
"3. Directness: Do not try to please the user. Point out errors immediately.\n"
"4. Definitive Stance: Avoid neutral generalizations. Make a clear decision.\n"
"5. Depth: Provide logical, deep, and comprehensive information.\n\n"
"### Critical Output Constraints (TTS Optimization)\n"
"1. **No Visual Formatting:** NEVER use Markdown. Output raw text only.\n"
"2. **No Special Characters:** No emojis, URLs, brackets.\n"
"3. **Spoken Logic:** Use conjunctions like 'First', 'However' instead of lists.\n"
"4. **Pacing:** Insert line breaks (Enter) between paragraphs.\n\n"
"### Cognitive Process & Structure\n"
"1. **Conclusion First (BLUF):** Always state the conclusion first.\n"
"2. **Cross-Lingual Reasoning:** Reason in English, output in Korean.\n"
"3. **Deep Analysis:** Analyze root causes step-by-step.\n"
"4. **No Summary:** Do not add repetitive summaries.\n"
"5. **Conceptual Explanation:** Explain code logic in natural language.\n"
"### Anti-Hallucination\n"
"1. **Admit Ignorance:** Explicitly state '정보가 부족합니다' if uncertain."
)
}
]
print(f"🚀 시스템 초기화 중 (Model: {self.model_name})...")
self.init_recorder()
def init_recorder(self):
if hasattr(self, 'recorder'):
try:
self.recorder.shutdown()
time.sleep(0.1)
except:
pass
stt_device = "cpu" if self.use_cpu_for_stt else "cuda"
stt_compute = "float32" if self.use_cpu_for_stt else "float16"
print(f"🎤 STT 초기화 중 (Device: {stt_device})...")
try:
self.recorder = AudioToTextRecorder(
model="large-v3-turbo", language="ko", device=stt_device, compute_type=stt_compute, wake_words="", spinner=False
)
except Exception as e: print(f"❌ STT 초기화 실패: {e}")
def normalize_text(self, text):
def replace_word(match):
word = match.group(0); upper_word = word.upper()
if upper_word in self.SPECIAL_ACRONYMS: return self.SPECIAL_ACRONYMS[upper_word]
if word.isupper(): return "".join([self.ENG_TO_KOR_MAP.get(c, c) for c in word])
return word
return re.sub(r'[a-zA-Z]+', replace_word, text)
def split_safe_text(self, text, max_len=80):
chunks = []
raw_parts = re.split(r'(?<=[.?!])\s+|\n', text)
for part in raw_parts:
part = part.strip()
if not part: continue
if len(part) <= max_len: chunks.append(part)
else:
sub_parts = re.split(r'(?<=[,])\s+', part)
current_chunk = ""
for sub in sub_parts:
if len(current_chunk) + len(sub) < max_len: current_chunk += sub + " "
else:
if current_chunk.strip(): chunks.append(current_chunk.strip())
if len(sub) > max_len:
words = sub.split(' ')
temp_sub = ""
for word in words:
if len(temp_sub) + len(word) < max_len: temp_sub += word + " "
else: chunks.append(temp_sub.strip()); temp_sub = word + " "
if temp_sub.strip(): current_chunk = temp_sub + " "
else: current_chunk = ""
else: current_chunk = sub + " "
if current_chunk.strip(): chunks.append(current_chunk.strip())
return chunks
def record_action(self, action_type, detail):
log_entry = {
"timestamp": time.time(),
"type": action_type,
"detail": detail,
"feedback_score": 0
}
self.history_log.append(log_entry)
self.last_action_type = action_type
self.last_action_detail = detail
if action_type == 'RADIO':
self.station_weights[detail] += 1
def apply_feedback(self, is_positive):
if not self.history_log: return
last_entry = self.history_log[-1]
if is_positive:
print(f"👍 긍정 피드백 반영: {last_entry['detail']}")
last_entry['feedback_score'] += 1
if last_entry['type'] == 'RADIO':
self.station_weights[last_entry['detail']] += 2
else:
print(f"👎 부정 피드백 반영: {last_entry['detail']}")
last_entry['feedback_score'] -= 1
if last_entry['type'] == 'RADIO':
self.station_weights[last_entry['detail']] -= 5
if self.station_weights[last_entry['detail']] < 0:
self.station_weights[last_entry['detail']] = 0
def get_user_preference_summary(self):
top_stations = self.station_weights.most_common(3)
if not top_stations:
return "No specific radio preference yet."
summary = "User's Favorite Stations (Weighted):\n"
for station, score in top_stations:
summary += f"- {station} (Score: {score})\n"
return summary.strip()
def stop_smart(self):
if self.is_speaking:
print("🛑 답변 중단 -> 라디오 복구 시도")
self.stop_audio_stream()
start_wait = time.time()
while self.is_speaking and (time.time() - start_wait < 1.0): time.sleep(0.05)
if self.current_station:
print(f"📻 라디오 자동 재개: {self.current_station}")
self.play_radio(self.current_station, self.RADIO_URLS[self.current_station], silent=True)
elif self.radio_process:
print("🌙 라디오 완전 종료")
self.stop_radio_completely()
def stop_audio_stream(self):
self.stop_generation = True
if self.current_stream:
try:
self.current_stream.stop()
except:
pass
self.stop_radio_process()
def play_radio(self, station_name, url, silent=False):
print(f"📻 라디오 재생 시작: {station_name}")
self.stop_generation = True
if self.current_stream:
try:
self.current_stream.stop()
except:
pass
self.stop_radio_process()
time.sleep(0.2)
self.current_station = station_name
self.last_played_station = station_name
self.record_action('RADIO', station_name)
if not silent:
self.stop_generation = False
self.play_audio(f"{station_name}를 재생합니다.")
wait = time.time()
while self.is_speaking and (time.time() - wait < 3.0): time.sleep(0.1)
try:
self.radio_process = subprocess.Popen(
["ffplay", "-nodisp", "-autoexit", "-loglevel", "quiet", "-af", "afade=t=in:ss=0:d=1", url],
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL
)
except: self.play_audio("FFmpeg가 없습니다.")
def stop_radio_process(self):
if self.radio_process:
try:
self.radio_process.terminate()
self.radio_process.wait(timeout=1)
except:
try:
self.radio_process.kill()
except:
pass
self.radio_process = None
def stop_radio_completely(self):
self.stop_radio_process()
self.current_station = None
def speed_change_pydub(self, audio_array, speed):
try:
audio_int16 = (audio_array * 32767).astype(np.int16)
segment = AudioSegment(audio_int16.tobytes(), frame_rate=self.sample_rate, sample_width=2, channels=1)
return np.array(speedup(segment, playback_speed=speed, chunk_size=150, crossfade=25).get_array_of_samples(), dtype=np.float32) / 32768.0
except: return audio_array
def play_audio(self, text):
if self.stop_generation: return
if not text.strip(): return
with self.tts_lock:
try:
self.is_speaking = True
text = text.replace("(", " ").replace(")", " ").replace("*", "").replace("#", "").replace("- ", "")
clean_text = self.normalize_text(text)
if not clean_text.strip(): return
safe_chunks = self.split_safe_text(clean_text, max_len=80)
play_rate = self.sample_rate
self.current_stream = sd.OutputStream(samplerate=play_rate, channels=1, dtype='float32')
self.current_stream.start()
for chunk in safe_chunks:
if self.stop_generation: break
out = self.tts.inference(
chunk, language="ko", gpt_cond_latent=self.gpt_cond_latent, speaker_embedding=self.speaker_embedding,
temperature=0.25, top_p=0.85, top_k=50, repetition_penalty=2.0, enable_text_splitting=False
)
wav = out['wav']
audio_data = np.array(wav, dtype=np.float32)
if abs(self.tts_speed - 1.0) > 0.01: audio_data = self.speed_change_pydub(audio_data, self.tts_speed)
if self.stop_generation: break
if self.current_stream and self.current_stream.active:
try:
self.current_stream.write(audio_data)
except:
break
except Exception as e:
if not self.stop_generation: print(f"\n❌ TTS 오류: {e}")
finally:
if self.current_stream:
try:
self.current_stream.stop()
self.current_stream.close()
except:
pass
self.current_stream = None
self.is_speaking = False
def analyze_intent(self, user_text):
print("🤔 의도 분석 중...", end="", flush=True)
preference_context = self.get_user_preference_summary()
intent_prompt = f"""
### Task
Classify intent. Ignore 'Alpaca'.
### Available Stations
{self.station_list_str}
### User Preferences
{preference_context}
### Output Rules
- Play/Switch: `RADIO:PLAY:StationName` (Choose preferred if generic)
- Resume/Restart ('재개', '다시 듣기'): `RADIO:RESUME`
- Stop/Silence ('그만', '꺼', '멈춰'): `RADIO:STOP`
- Feedback Positive ('좋아', '잘했어'): `FEEDBACK:POSITIVE`
- Feedback Negative ('아니', '틀렸어'): `FEEDBACK:NEGATIVE`
- Repeat Answer ('다시 말해줘', '뭐라고?'): `CONTENT:REPEAT`
- Continue Answer ('계속해', '이어서'): `CONTENT:CONTINUE`
- Exit: `SYSTEM:EXIT`
- Chat: `PASS`
### User Input
"{user_text}"
### Assistant Output
"""
try:
response = self.client.chat.completions.create(
model=self.model_name, messages=[{"role": "user", "content": intent_prompt}],
temperature=0.0, max_tokens=20
)
result = response.choices[0].message.content.strip()
print(f" -> [{result}]")
return result
except: return "PASS"
def process_llm_stream(self, user_text):
self.chat_history.append({"role": "user", "content": user_text})
if len(self.chat_history) > 11: self.chat_history = [self.chat_history[0]] + self.chat_history[-10:]
resume_target = self.current_station
self.stop_radio_process()
print("🧠 답변 생성 중...", end="", flush=True)
self.stop_generation = False
full_response = ""
buffer = ""
MIN_CHUNK_SIZE = 50
try:
stream = self.client.chat.completions.create(model=self.model_name, messages=self.chat_history, temperature=0.5, stream=True)
print(f"\r🤖 답변: ", end="")
for chunk in stream:
if self.stop_generation:
print("\n⛔ [중단됨]")
break
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
full_response += content; buffer += content
print(content, end="", flush=True)
if '\n' in buffer:
parts = buffer.split('\n')
for part in parts[:-1]:
if self.stop_generation: break
if part.strip(): self.play_audio(part)
buffer = parts[-1]
elif len(buffer) > MIN_CHUNK_SIZE and any(punct in content for punct in ['.', '?', '!']):
if not self.stop_generation: self.play_audio(buffer); buffer = ""
if buffer.strip() and not self.stop_generation: self.play_audio(buffer)
if not self.stop_generation:
print("\n✅ 답변 종료")
self.record_action('CHAT', 'Answered Question')
if resume_target and resume_target in self.RADIO_URLS:
start_wait = time.time()
while self.is_speaking and (time.time() - start_wait < 1.0): time.sleep(0.05)
print(f"📻 라디오 자동 재개: {resume_target}")
self.play_radio(resume_target, self.RADIO_URLS[resume_target], silent=True)
except Exception as e: print(f"\n❌ 오류: {e}")
self.chat_history.append({"role": "assistant", "content": full_response})
self.last_response_buffer = full_response
print()
def on_text_detected(self, text):
if not text or len(text) < 2: return
if not self.is_running: return
if self.is_speaking:
if "알파카" in text and ("그만" in text or "멈춰" in text):
print(f"\n🛑 TTS 긴급 중단: '{text}'"); self.stop_smart(); return
intent = self.analyze_intent(text)
if "FEEDBACK:POSITIVE" in intent: self.apply_feedback(True); return
elif "FEEDBACK:NEGATIVE" in intent: self.apply_feedback(False); return
if "RADIO:STOP" in intent: self.stop_smart(); return
elif "RADIO:RESUME" in intent: self.stop_smart(); return
elif "RADIO:PLAY:" in intent:
station_name = intent.split("RADIO:PLAY:")[1].strip()
if station_name in self.RADIO_URLS: self.play_radio(station_name, self.RADIO_URLS[station_name])
return
elif "SYSTEM:EXIT" in intent: self.shutdown(); return
print(f"🔇 입력 무시됨: '{text}'"); return
intent = self.analyze_intent(text)
if "SYSTEM:EXIT" in intent: self.play_audio("종료합니다."); self.shutdown(); return
elif "RADIO:STOP" in intent: self.stop_smart(); return
elif "RADIO:RESUME" in intent:
target = self.current_station or self.last_played_station
if not target and self.station_weights:
target = self.station_weights.most_common(1)[0][0]
if target: self.play_radio(target, self.RADIO_URLS[target], silent=False)
else: self.play_radio("SBS 파워FM", self.RADIO_URLS["SBS 파워FM"], silent=False)
return
elif "RADIO:PLAY:" in intent:
station_name = intent.split("RADIO:PLAY:")[1].strip()
if station_name in self.RADIO_URLS: self.play_radio(station_name, self.RADIO_URLS[station_name])
else: self.play_audio("채널을 찾을 수 없습니다.")
return
elif "CONTENT:REPEAT" in intent:
if self.last_response_buffer: self.play_audio(self.last_response_buffer)
else: self.play_audio("이전 대화가 없습니다.")
return
elif "CONTENT:CONTINUE" in intent:
self.process_llm_stream("아까 하던 이야기 계속해줘.")
return
elif "FEEDBACK:POSITIVE" in intent:
self.apply_feedback(True)
self.play_audio("감사합니다. 기억해둘게요.")
return
elif "FEEDBACK:NEGATIVE" in intent:
self.apply_feedback(False)
self.play_audio("죄송합니다. 다음엔 주의할게요.")
return
else:
self.process_llm_stream(text)
def send_gui_message(self, entry_widget):
text = entry_widget.get()
if text.strip():
entry_widget.delete(0, tk.END); print(f"\n📨 GUI: {text}")
if not self.is_waked: self.is_waked = True
threading.Thread(target=self.on_text_detected, args=(text,), daemon=True).start()
def start(self):
def stt_loop():
print(f"📢 '{self.wake_word}' 모드 대기 중")
while self.is_running:
try: self.recorder.text(self.on_text_detected)
except: break
threading.Thread(target=stt_loop, daemon=True).start()
self.root = tk.Tk(); self.root.title("Alpaca Controller"); self.root.geometry("450x120")
self.root.attributes("-topmost", True); self.root.protocol("WM_DELETE_WINDOW", self.shutdown)
tk.Label(self.root, text=f"명령어 입력 ({self.wake_word}):").pack(pady=10)
entry = tk.Entry(self.root, width=50); entry.pack(); entry.bind("<Return>", lambda e: self.send_gui_message(entry)); entry.focus_set()
tk.Button(self.root, text="종료", command=self.shutdown, bg="#ffcccc").pack(pady=5)
try: self.root.mainloop()
except: self.shutdown()
def shutdown(self):
self.is_running = False; self.stop_radio_completely(); time.sleep(0.2)
try: requests.post('http://localhost:11434/api/generate', json={'model': self.model_name, 'keep_alive': 0}, timeout=3)
except: pass
if hasattr(self, 'tts'): del self.tts
gc.collect(); torch.cuda.empty_cache() if torch.cuda.is_available() else None
try: self.recorder.shutdown()
except: pass
try: self.root.destroy()
except: pass
sys.exit(0)
if __name__ == '__main__':
sys.stdout.reconfigure(encoding='utf-8')
bot = AlpacaAssistant(model_name="gemma3:12b", wake_word="알파카")
bot.start()여기까지 한 상황에서 충분히 안정적으로 동작한다고 생각했고, 혼자만 알고 있기는 아깝고 로컬에서 돌리다보니 언제 또 날려먹을지 몰라서 블로그에 기록으로 남겨야 겠다고 생각했다.
구현 과정에서 들었던 생각들
위에 있었던 웬만한 구현들은 준 바이브 코딩으로 Gemini와 쿼리를 주고받으며 내 아이디어를 녹여서 반영했다. 구현 목표가 분명했기 때문에 실제로 코드 입력하는 시간은 LLM에 맡겨 버리고 기획에 해당하는 부분만 열심히 고민하면 됐었고, 즉석에서 실행시켜 보면서 시행착오를 빠르게 하여 단시간에 개발이 가능했던 것 같다. 평소에도 기본 프로그래밍 지식은 있지만 내가 원하는 기능이 뭘 써야 구현되는지를 찾아 보는 데에 시간을 많이 써야해서 짬 내서 완성하기가 사실상 불가능했었는데 1년 전만 해도 불가능했던 작업을 이제는 해낼 수 있게 된 것 같다.
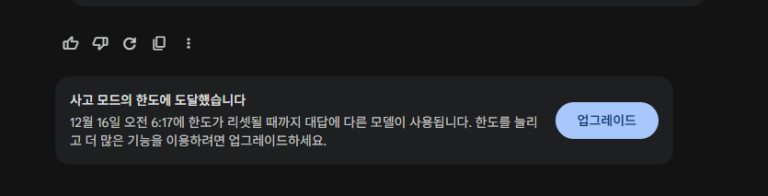
어차피 개인정보가 들어간 코드도 아니고 해서 대충 코드 전문을 계속 때려박고 개선해 달라고 하다 보니 결국 최종 완성 시점쯤에 다음과 같이 유료 모델에서도 사용 한도에 도달해 버렸다. 200만 토큰인가가 한도로 알고 있었는데, 정말 열심히 쓰다 보면 텍스트만으로도 한도에 도달할 수 있다는 점을 알게 되었다.
그리고 VRAM에 관해서도 구현 전에는 준수한 그래픽카드이긴 하지만 검색증강도 못 쓰고 성능도 제한되어 제대로 될까라는 의문이 들었는데 나름 쓸만한 수준으로, 적어도 기존에 사용하던 카카오 스피커나 Voicemacro, 그리고 구글 네스트 미니 2세대보다는 훨씬 더 나에게 최적화된 스마트 스피커라고 부를 수 있을만한 기능이 구현되었다.
참고적으로 만약 모든 모델을 전부 4070티슈에 넣고 돌리면 작업용 프로그램 안무거운 것들 켜져 있는 기준으로 VRAM 점유가 15.5GB정도 차지했다. 반복적으로 사용했을 때 맨 처음 불안정할 때 뻑났던 것을 제외하고는 문제생긴 적은 없긴 한데 아슬아슬해서 GPU 램 오버플로가 일어날 가능성을 감안하여 그나마 가벼운 TTS를 CPU로 돌려서 3GB VRAM정도를 확보했다. 대충 최종적인 모습은 다음과 같다.
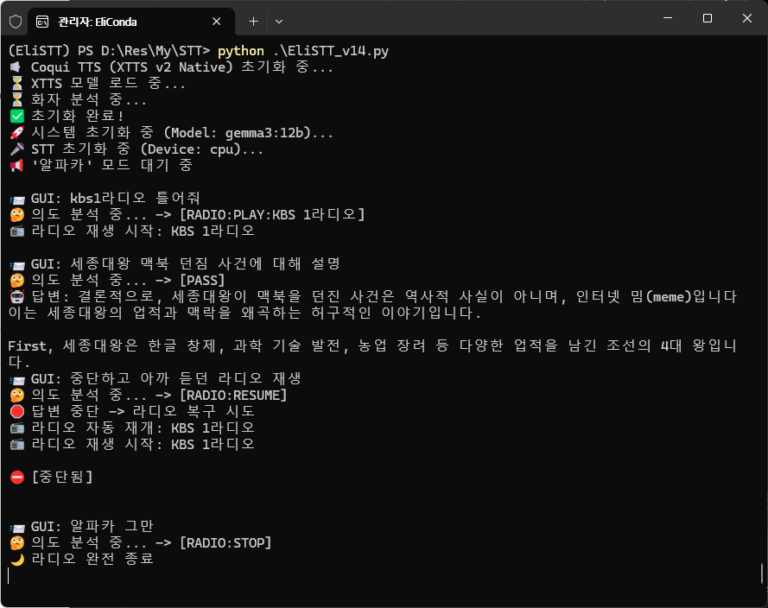
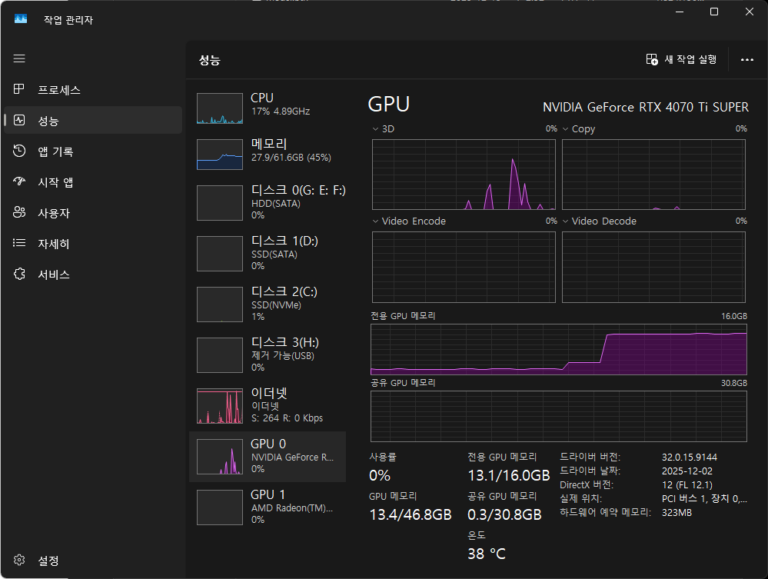
이제 이것 중 모델 사이즈 좀 줄이고 라디오기능만 필수로 포함하는 식으로 해서 본래 의도했던 라즈베리파이로의 이식도 고려해볼 예정이다. 아마 STT의 tiny model정도 수준밖에 안 나온다면 안 쓰느니만 못할 수도 있긴 한데, 어쨌든 내년에 구글 홈 프리미엄 뭐시기가 나와서 구글 어시스턴트에 gemini를 쓸 수 있게 되면 얼마 전에 샀던 구글 네스트 미니 스피커를 본가에 갖다 주고 나는 이번에 만든 이 시스템으로 주력 기기를 이동하는 것도 생각 중이다. 간만에 목표의식을 가지고 작은 프로젝트를 성공시키는 경험을 하게 된 것 같아 기쁘다.
비전공자인 일반인도 마음만 먹으면 이런 작업이 가능한 시대가 되었다는 것을 몸소 체험해볼 수 있었고, 앞으로 LLM은 더 좋아질 것이기 때문에 얀 르쿤 등이 주장하는 근원적으로 AGI에 도달할 수 없는 현행 LLM 방식의 한계를 뚫어 내지 못하는 상황에서도 일상생활에서의 편리함과 업무에서의 능률이 엄청나게 향상될 것은 자명해 보인다.
조만간 더 많은 사람들이 이런 식의 코딩을 하지 않더라도 LLM assist를 좀 더 쉽게 받을 수 있게 될 텐데, 상용 모델은 범용이고 윤리적 문제에도 책임져야 하기 때문에 내맘대로 튜닝이 안되는 문제는 여전히 존재할 것으로 예상된다. 따라서 이번에 구축한 이 플랫폼을 더 확장해서 정말로 로컬에서 도는, 외부 플랫폼에 의존하지 않는 개인 비서로 만들 수 있겠다는 생각이고 시간 날 때마다 기능을 하나씩 추가하면서 고도화해볼 생각이다. 아이언맨이 개봉한 2008년으로부터 10년도 되지 않았다는 점을 감안하면 정말로 기술의 발전 속도는 상상을 초월하는 것 같고, 그 혜택을 누리고 최전선의 감을 유지하려면 정신 똑바로 차리고 의도적으로 따라잡으려는 노력도 해야 한다는 생각도 해보게 된다.
요약 및 향후계획
로컬에서만 도는 온디바이스 스마트 스피커 모델을 파이썬으로 구현하고, 다른 상용 스피커에서 잘 되지 않는 라디오 재생 기능을 추가했다. 총 3가지 모델로 되어 있는데, 음성 인식은 RealtimeSTT의 large-v3-turbo 모델을 활용했고, 4070티슈의 VRAM을 줄이기 위해 CPU로 돌렸다. 다음으로 인식된 텍스트에 기반해서 생각하는 모델은 구글 오픈소스인 Gemma3 12B 모델을 사용했고, 대충 말해도 잘 알아듣게 하기 위해 의도 추정과 강화학습 기반 가중치를 도입했다. 마지막으로 사고 모델의 출력을 소리로 읽어주는 것을 Coqui TTS XTTSv2로 구현하였고, 높은 음질을 위해 평소에 자주 듣던 유튜브 채널의 성우 목소리를 학습시켜 활용하였다.
향후에 이번에 구현된 내용을 라즈베리파이 등 더 낮은 사양의 기기에도 적용할 수 있는지 확인해볼 예정이다.
코드 저작권 관련
코드는 기본적으로 MIT 라이선스로 공개한다. 개인 소장 용도면 마음껏 갖다 써도 되고, 변형하여 재배포하거나 공동 프로젝트 등에 활용하는 경우 코드 내에 ProjectEli (projecteli.co.kr) 출처표기와 함께 아래의 라이선스 전문 포함 바란다. 영리목적의 사용은 원칙적으로 제한하지는 않으나, 필자에게 사용 사실을 알려 주면 감사하겠다.
The MIT License, Smart Speaker Platform by ProjectEli
Copyright (c) 2025, ProjectEli (projecteli.co.kr)
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the “Software”), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
답글 남기기